
Winning the Benchmarks, Losing the Market
America still builds the best AI models in the world. The market is about to learn that owning the best model is not the same as owning the most valuable one.

TLDR
Last week, Coinbase moved its engineers off the American AI frontier and onto two open-weight models from China. Its AI bill fell close to 50%. Usage kept climbing.
That is the whole thesis in one move. The US still leads in raw capability. It is losing on the thing that actually decides revenue: what companies run in production, and what it costs them per token.
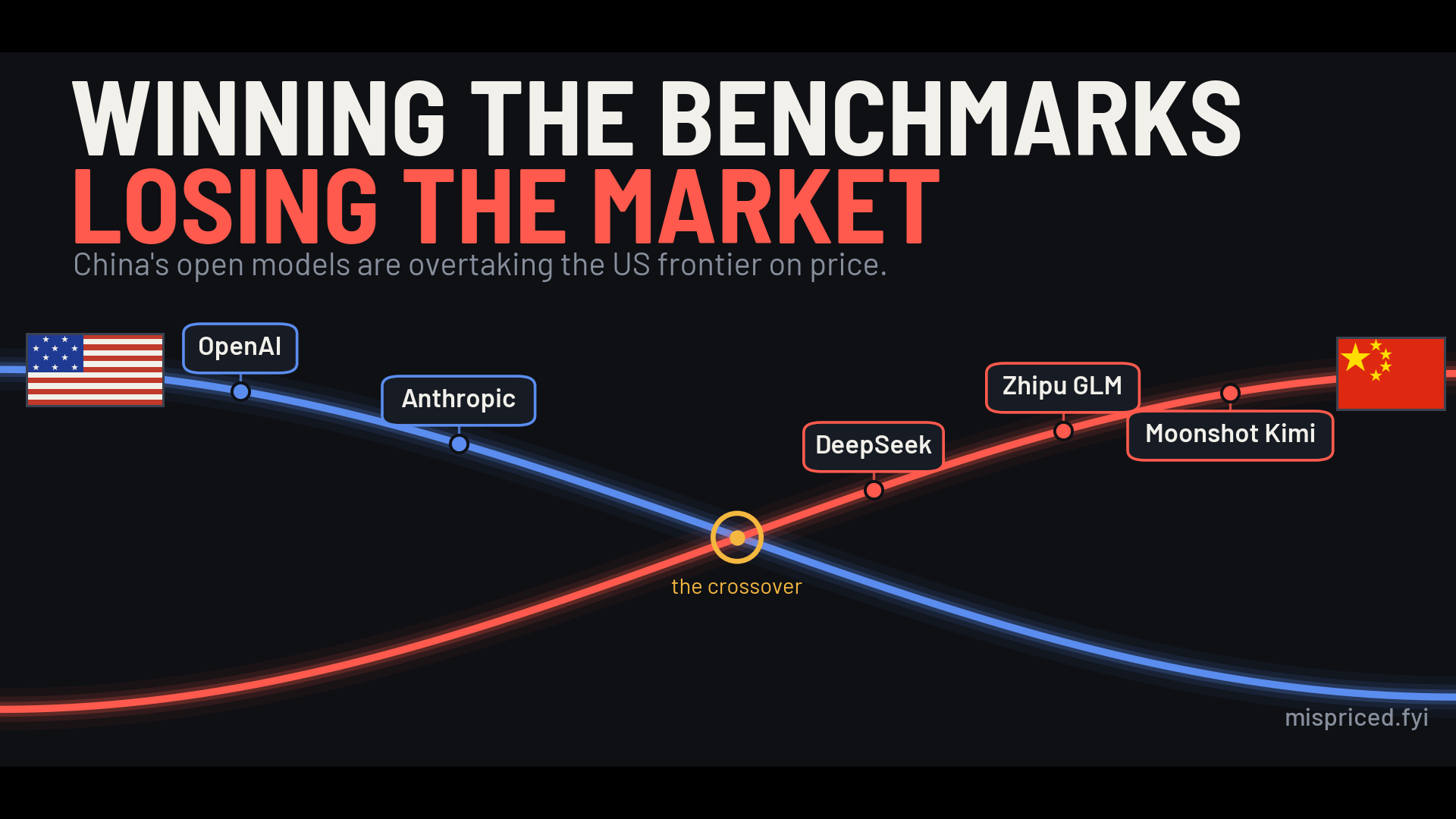
This is not a collapse. The frontier still matters, and America still owns it. But the market is pricing that lead as a moat when the usage data says it is a margin, and a margin is a very different thing to own.
The leading indicator is already public. On OpenRouter, where developers route real workloads, the US share of tokens fell from ~70% to ~30% in 12 months. Both US frontier labs filed to go public in June, at the exact moment their pricing power is being questioned at both ends. Here’s the full case.
---
The switch that should bother the bulls
Brian Armstrong runs Coinbase, one of the largest public crypto companies in the world. Last week he changed one setting.
He moved his engineers’ default model off the US frontier and onto GLM 5.2 from Zhipu and Kimi from Moonshot. Both are open-weight. Both are Chinese.
He did not frame it as geopolitics. He framed it as arithmetic. 91% of his engineers had never once hit their old usage limits.

So instead of rationing access, he switched the default to models that cost a fraction of the American ones. He kept the expensive US frontier on hand for the genuinely hard jobs. The bill dropped by ~50% while usage rose.
He was not first. Months earlier, Flo Crivello took his AI agent company Lindy entirely off Claude and onto DeepSeek. He did not talk about which model was smarter either. He talked about survival.
One company changing one default is not a story. It is an anecdote, and anecdotes are cheap.
But Coinbase is an early instrument reading, the first gauge to move in public before the rest of the panel catches up. What it is registering is the most important thing in AI right now that the market has not priced.
Two scoreboards
There are two ways to keep score in AI, and they have quietly come apart.
The first scoreboard measures capability. Who has the smartest model, the largest training run, the most chips, the top benchmark? On this board, the US is comfortably ahead.
The second scoreboard measures what people actually run and what it costs per token. This is the board that decides who collects the revenue.
The cleanest public read on it is OpenRouter, where developers route real workloads across hundreds of models with no contract and no lock-in. Nobody routes an app to a model out of loyalty. They route it to whatever does the job at a price they can live with.

On that second board, the picture has inverted fast. A year ago, around June 2025, US models were roughly 70% of the tokens flowing through OpenRouter.
By June 2026, that share was about 30%. Chinese models crossed US ones for the first time in February, and by spring, they were the clear majority.
The market is pricing American AI off the first scoreboard. The cash is being decided on the second.
Act one: the bottom fell out on price
To see why whole companies are voting the way they are, start with the model that set off the latest stampede.
In mid-June, the Chinese lab Zhipu released GLM 5.2, an open-weight model anyone can download and run on their own hardware. Its scorecard reset the conversation.
On the coding benchmarks that decide real engineering work, GLM 5.2 landed within 1 point of Claude Opus 4.8, the model at the top of the capability rankings. It beat OpenAI’s GPT-5.5 outright on the same tests.

The honest version matters more than the hype. Claude still holds the top score on most of these benchmarks, and China has not suddenly built something smarter than the US frontier.
What it has built is something close enough that the gap rounds away on most real work. Then it released that for nothing.
Now set the price beside the score. GLM 5.2 runs at about $4.40 per million output tokens.
Claude Opus 4.8 charges $25. GPT-5.5 charges $30. That is 5 to 6 times cheaper for work that scores within a point, and the floor is lower still, with DeepSeek’s open model under $1.

This stopped being a story about a cheap tier losing to a premium one on quality. It became a story about the premium tier’s quality lead shrinking to a rounding error while its price stayed 5 to 6 times higher.
And the squeeze lands hardest where the volume is going. Coding grew from ~10% of OpenRouter usage at the start of last year to more than 50% today.
Coding is both the most price-sensitive workload in the building and the one where the open Chinese models are strongest.
The old reassurance was that cheap models were toys and serious money would always pay up. GLM 5.2 retired that argument.
When an open model matches the closed one within a point and costs a sixth as much to run, the burden of proof flips. Every team with a finance function eventually has to explain why it continues to pay the premium.
The counterargument that died in June
The bull’s best response is that enterprises do not actually behave this way. They standardize on a trusted vendor, sign a contract, and stop optimizing.
That counterargument died in June. UBS, surveying companies that actually track their AI spend, found that around 60% have begun imposing hard limits on token usage.

These are not penny-pinching startups. These are the buyers the premium case depends on, and they are watching the meter.
The spend behind that caution is exploding. By CloudZero’s count, the share of organizations planning to spend over $100K a month on AI doubled from 20% in 2024 to 45% in 2025.

When the bill gets that big, a 5x price gap stops being a line item and becomes a board-level decision. That is exactly the moment a 50% cut from switching defaults becomes irresistible.
They are raising prices into the war
Here is the part that should worry anyone underwriting US pricing power. The American labs are raising prices, not cutting them, right as the cheaper rivals arrive.
By JPMorgan’s reading, OpenAI roughly doubled token prices between two recent generations. Premium-tier increases ran 3x to 9x, and a handful of users reported moves as steep as 100x.

Take the steepest number with a grain of salt, since it is user-reported rather than a clean measurement. Take the direction seriously.
You raise prices into a war like that only if you believe your product has no substitute. The OpenRouter data says the substitute has already shipped.
Two weeks in June
Then the US government did something genuinely new, and it cut the wrong way.
On June 12, the Commerce Department recalled Anthropic’s two most capable models, Mythos 5 and Fable 5, under an export-control directive. They were barred from all foreign nationals, including Anthropic’s own non-citizen staff.
Anthropic pulled both worldwide. The NSA and the UK’s AI Safety Institute, one of the most important model-testing bodies in the world, lost access in the process.

The government did not restrict these models because they were weak. It restricted them because they were too good at finding software vulnerabilities, a capability that cuts both ways.
The episode bred its own scandal when a general told the Senate that in an authorized exercise, Mythos broke into nearly all of an agency’s classified systems in hours.
That line raced around the internet as “AI hacked the NSA.” It had not. It was a controlled red-team test, the agency pointing the model at its own networks, and Anthropic’s position is that the underlying research was for defense.
Now watch the backfire. Within days of the ban, Zhipu shipped an open-weight model that security researchers found could beat Anthropic’s publicly available coding models at exactly that kind of vulnerability detection.

The careful version is still the damning one. The capability the US went to extraordinary lengths to contain is now free, open, and downloadable by anyone with a graphics card.
You cannot recall a model that has already been downloaded 100,000 times. An export-gated frontier model cannot win a global market, because most of the world is the set of customers it is now forbidden to serve.
And when the best American model is unavailable, the global default does not become the second-best American model. It becomes the Chinese open weight with no kill switch and no government letter that can arrive on a Friday and shut it off.
The mispricing, named
Step back, and the shape is clear. By JPMorgan’s own count, the AI trade has driven somewhere between 65% and 80% of the S&P 500’s returns, earnings, and capital spending since ChatGPT launched.

The entire index is leaning on one bet, and that bet assumes US capability is a durable moat that converts into a durable margin. The two scoreboards say the moat is real, but the conversion is broken.
The numbers underneath do not help. JPMorgan’s midyear outlook raised total AI capital spending to $5.5T through 2030, most of it debt-financed.
To earn even a 10% return on that buildout, the industry needs roughly $650B of revenue every year, in perpetuity. The bank illustrated that as $35 a month from every iPhone user on the planet, or $180 from every Netflix subscriber.

Today, the industry spends roughly $8 to $10 of capital for every $1 of revenue it earns. It is funding hardware that wears out in about a year with debt that assumes a useful life of 7 to 15.
There is even a circularity propping up reported profit. Last quarter the catch-all “other income” line made up 60% of Google’s profit, 51% of Amazon’s, and 27% of NVIDIA’s.
A meaningful slice of that is gains these companies book from marking up their own stakes in OpenAI and Anthropic. The hyperscalers fund the labs, the labs spend it on the hyperscalers’ chips, and everyone revalues everyone else upward.
It is not fraud. It is a loop, and loops look like growth right up until they do not.
All of this sat in plain sight while valuations stayed anchored to the first scoreboard. Then, in the last week of June, the second scoreboard reached the tape.
Korean markets, home to the memory chipmakers at the center of the buildout, tripped their circuit breakers twice in one morning. Samsung and SK Hynix shed roughly 10% of their value, and the selling spread to the Nasdaq.

The market started to price the problem. It just did it for the wrong reason, panicking about debt and valuation, when the deeper mechanism is quieter: demand is migrating to a substitute that needs far less capital.
And the two labs at the center of the trade both filed to go public in June. Anthropic first, at a private valuation near $965B, with an October listing in view. OpenAI days later, around $$852B.

Combined, that is roughly $1.8T racing to sell shares into the public market at the exact moment their pricing power is being questioned at both ends.
Where I could be wrong
A thesis you cannot argue against is a mood, not a thesis. So here is the honest other side.
The migration could be slower than it looks. Some of the falling prices reflect US labs getting more efficient at inference, not customers fleeing to China, and the evidence on open-model adoption is still early.
UBS frames its own finding as growth moderating, not demand reversing. Spending that was tracking toward 150 is landing nearer to 120 to 130. That is a haircut, not a collapse.
The frontier genuinely matters and is not going away. The hardest work, in cybersecurity defense, in scientific discovery, in long-horizon agents, still wants the best model regardless of price, and that tier is American.
This is bifurcation, not extinction. A vast commodity layer that China wins on cost, and a smaller premium layer where US labs keep real pricing power.
This piece is about that foundation-model layer and the capital cycle funding it. It is not about application-layer software serving real customers at real enterprise scale, which runs on completely different unit economics.
As a solution consultant at Adobe, I have watched augmentation deployments work when scoped correctly, and Forrester’s Total Economic Impact studies show the same shape: triple-digit ROI when the use case is tight, near-zero when companies try to remove humans from the workflow entirely.
The bull case is not stupid. It is measuring the wrong board, and underwriting the whole index on the assumption that the premium tier is most of the prize, when the usage data says it is the minority.
What to watch
If this read is right, it shows up in specific, checkable places over the next few quarters.
Watch whether hyperscaler inference pricing starts to compress and whether margin guidance softens. Watch whether the premium tier narrows from a general-purpose default to a niche reserved for high-stakes work.
Watch the two IPOs, and whether the bankers can hold their valuations once the prospectuses force the unit economics into daylight.
And watch the open-weight share on the second scoreboard. That single line is the leading indicator for whether the revenue JPMorgan needs ever actually arrives.
America still builds the best AI in the world. That part is true and worth saying clearly.
But the market is pricing that lead as a moat, when the evidence says it is a margin, contested from below on price and constrained from above by the government. One of those justifies the valuations. The other does not.
The best models in the world, priced like a monopoly, were sold into a market that had already found a cheaper substitute.
A margin wearing the price tag of a moat.
The American AI trade is mispriced.