
OpenAI and Anthropic Have a Token Problem. Token Yield Is the Moat.
The panic over AI bills is real, and it killed tokenmaxxing. But the fixes going viral, caveman prompts and a hunt for cheaper models, aim at the wrong target.


TL;DR
- The AI cost panic of 2026 is real. Uber burned its annual AI budget in four months, Microsoft cancelled Claude Code for whole divisions, and the labs ended subsidized pricing. Tokenmaxxing, the practice of gaming raw token usage, is over. Fortune wrote the obituary in May.
- The viral fixes miss the point. The “caveman” prompt that promised 75% savings delivers 14 to 21, sometimes costs more, and where it does save, the real lever was a hidden reasoning setting, not the broken grammar.
- The waste was never in the prompt. It lives in the system around the model: retrieved context, tool schemas, reasoning traces, and memory. Token efficiency is an architecture problem, not a model-pricing one.
- The whole field already knows this. The discipline moved from prompt engineering to context engineering to harness engineering, and the operative metric in 2026 is cache-hit rate, not prompt quality.
- More tokens is not just costlier, it is worse. Every frontier model tested degrades as context grows. Curated context is cheaper and sharper.
- That is the moat. Value accrues to whoever owns the architecture that turns tokens into work. The labs commoditize raw capability; the layer that owns the system of work keeps the margin.
---
The most popular fix was to make the AI talk like a caveman
For a few weeks this spring, the most popular answer to the AI cost crisis was to make the model speak like a caveman.
A prompt skill called Caveman went up on GitHub and collected four thousand stars in days. The pitch was simple and seductive. Strip the articles, the pleasantries, the connective grammar, and instruct the model to answer in dense fragments. No “sure, happy to help.” No “you can use a JOIN operation to combine data from two tables based on a common key.” Just: use JOIN. The headline claim was a seventy-five percent cut in tokens.
It does not deliver that, and the way it fails is the whole story. When developers actually benchmarked the skill on Claude, the real savings landed between fourteen and twenty-one percent, and a stripped-down six-line version outperformed the full skill on every run.
On coding tasks it frequently backfired, returning more tokens than a plain instruction to be concise, because the model started adding telegraphic annotations and quietly expanding the scope of the work it was asked to do. And the single case where someone measured a genuine eleven-fold reduction had nothing to do with caveman grammar at all.
A classifier buried in the coding harness had silently switched the model into extended-thinking mode and burned roughly two thousand reasoning tokens before writing one visible word. Pin the reasoning effort low and the identical answer cost two hundred tokens instead of two thousand.
That is the AI cost panic in a single anecdote. Everyone went hunting for waste in the words they could see, and the waste was somewhere else entirely.
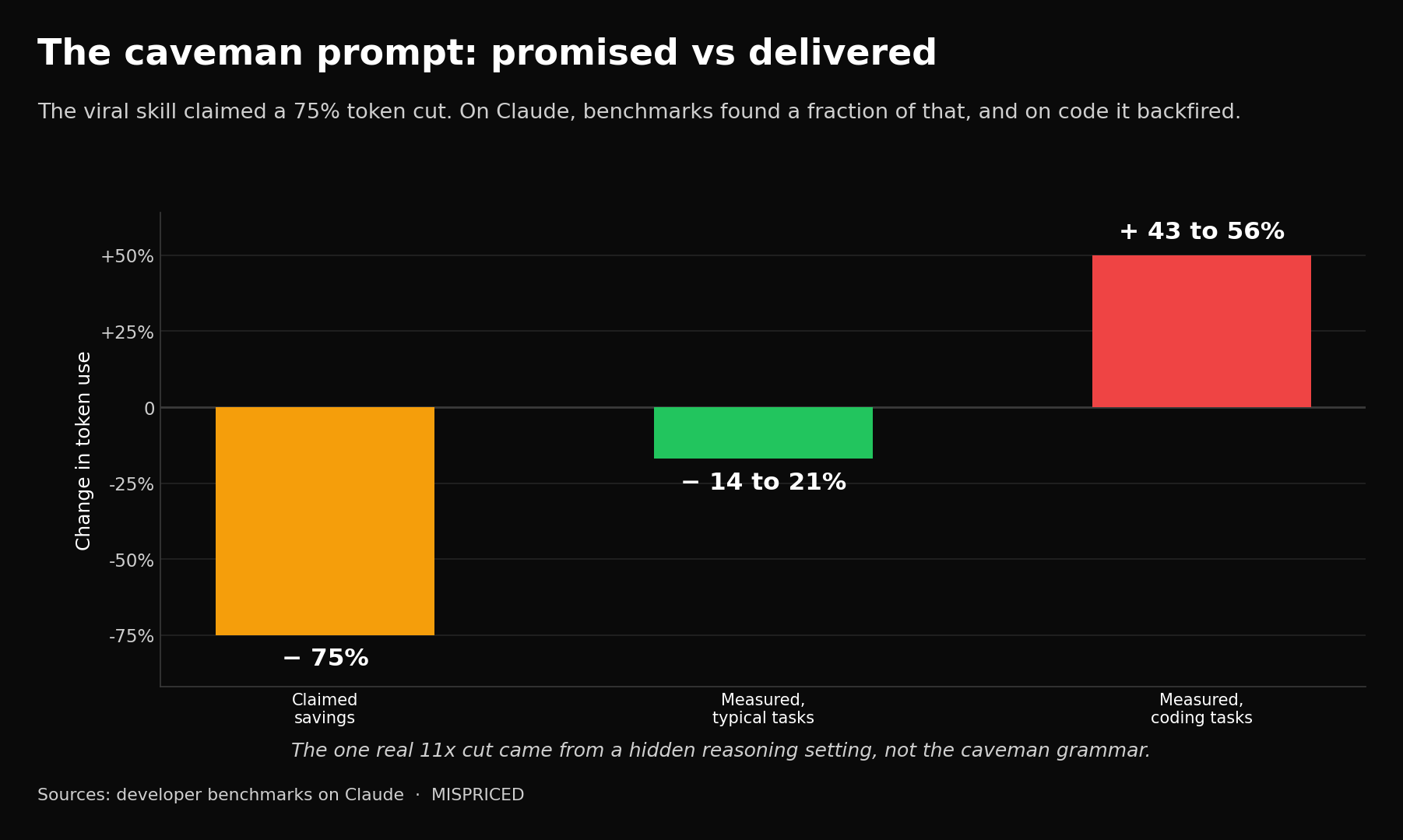
[The caveman prompt, promised vs delivered. Claimed 75% token savings against a measured 14-21% on typical tasks, and a 43-56% increase on coding. Sources: developer benchmarks on Claude.]
The panic is real, and tokenmaxxing is the casualty
None of this means the bills are imaginary. They are enormous, and they arrived faster than anyone budgeted. Uber capped employees at fifteen hundred dollars apiece after burning its entire 2026 AI budget in four months. Microsoft cancelled Claude Code subscriptions across several product divisions. Ramp’s own data shows average monthly token consumption up thirteenfold since the start of 2025, even as the dollars spent rose only fourfold, the gap being the falling price of a token. And the subsidy that hid all of it is ending: Anthropic began charging Claude Enterprise the full cost of compute in April, and GitHub moved Copilot to usage-based billing on June 1, citing inference costs it could no longer absorb.
The cultural artifact of that era was the leaderboard. Amazon, Meta, and others ran internal dashboards that ranked employees by token consumption, which produced precisely the behavior you would expect, engineers throwing trivial work at expensive models all day to climb the rankings. The practice earned a name, tokenmaxxing, and for about a year it stood in as a proxy for how seriously a company was taking AI. It was always a bad proxy. In May, Fortune declared it dead, calling it a flawed way to measure return on AI. Ramp’s CEO, whose company just raised seven hundred and fifty million dollars to help finance teams track exactly this spend, called it the twilight of tokenmaxxing.
What replaces it is a different question. Not how many tokens a system consumes, but how much useful work it produces per token. Glean’s CEO Arvind Jain gave the metric a name, token yield, and because Glean sells enterprise search built around precisely this idea, treat the framing as both sharp and self-interested. The metric is bigger than any one vendor, and the rest of this piece is the case for why.
The tokens are not where you are looking
Start with where the spend actually goes, because it is not the prompt.
In any real agentic system, the user’s question is a sliver of the tokens in play. The bulk is everything the system wraps around it: the system instructions, the schemas describing every tool the agent can call, the documents retrieved to ground the answer, the model’s own reasoning traces, and the memory of prior turns. Agentic loops then compound the problem, because each step re-sends the accumulated context, and the cost of a long session grows quadratically with its length. A single misconfigured run can produce a bill of hundreds of dollars over a weekend, and almost none of it is the words the user typed.
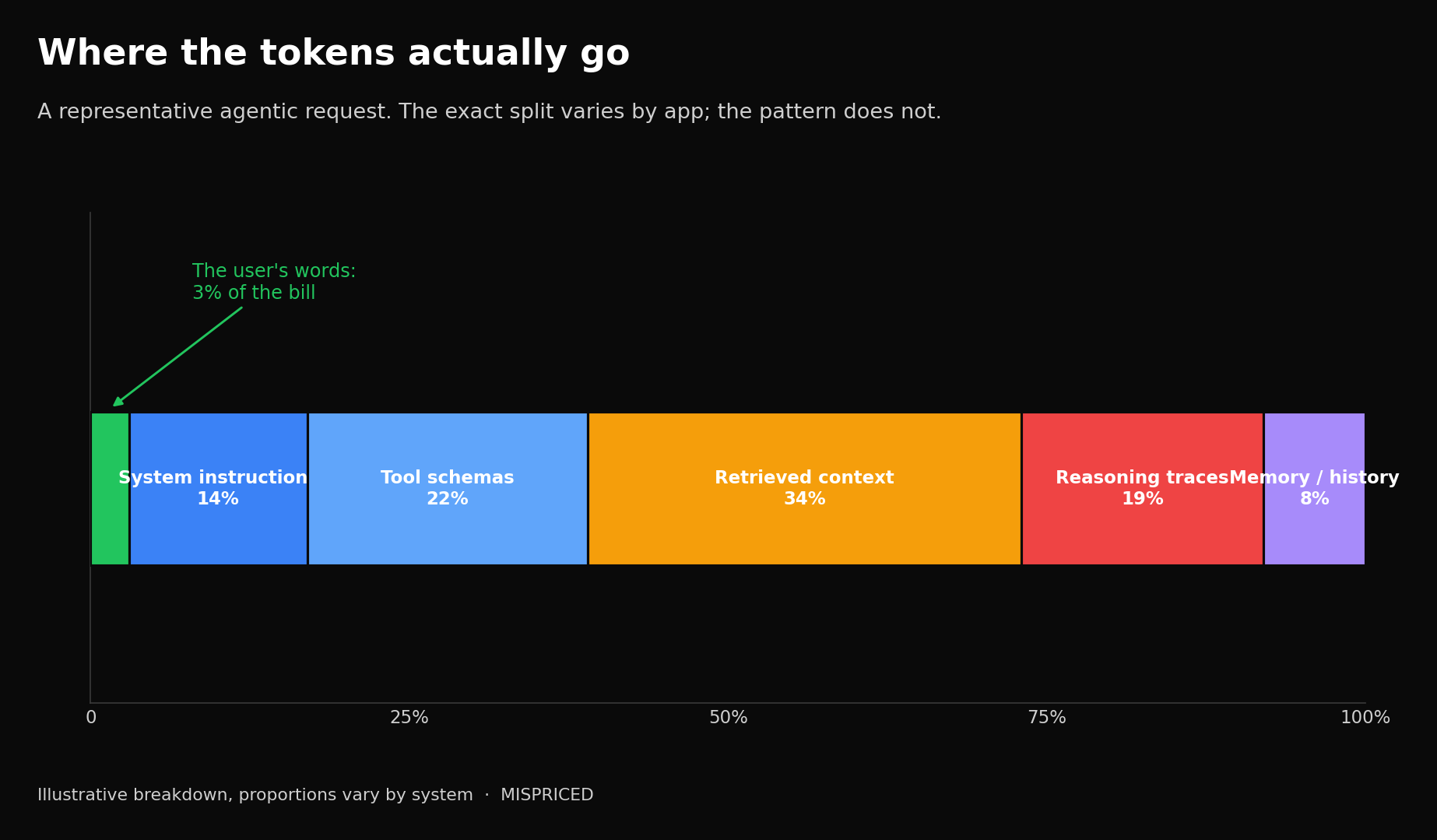
[Where the tokens actually go. The real token load of a single “small” agentic request: system instructions, tool schemas, retrieved context, reasoning traces, and memory dwarf the user’s prompt.]
Which leads to the conclusion the caveman crowd skipped past. Token efficiency is not a model-pricing problem you solve by shopping for a cheaper API or trimming your prose. It is an architecture problem, and it lives in the design of the system, not the phrasing of the request. Jain put it plainly in the post that named the metric: the waste is in the system design, not the prompt.
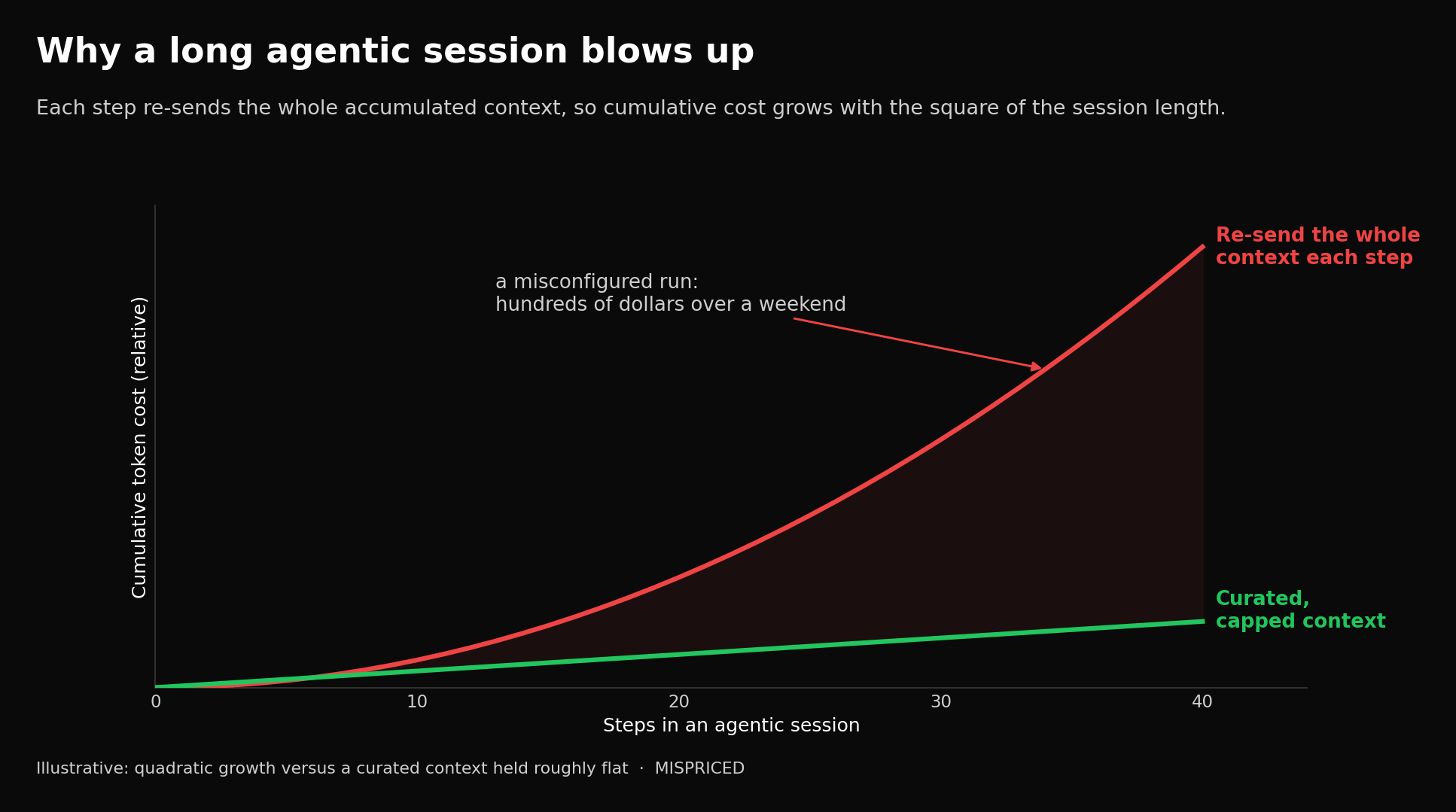
[Why a long agentic session blows up. Each step re-sends the whole accumulated context, so the cumulative cost grows with the square of the session length, unless it is curated. Illustrative.]
The field already moved; the income statements just haven’t
This is not a contrarian take. It is the consensus that the entire field has reached over the past year, and the only thing lagging is the accounting.
The discipline even has a name and a dated lineage. In June 2025, Shopify CEO Tobi Lütke described the real skill as context engineering, the art of supplying all the context a task needs to be plausibly solvable by the model. Andrej Karpathy endorsed the term a week later, calling it the delicate art and science of filling the context window with just the right information for the next step. The institutions ratified it from there.
Anthropic formalized context engineering in September 2025 as the strategies for curating the optimal set of tokens during inference. Gartner published research under the blunt headline that context engineering is in and prompt engineering is out. By 2026, the frontier had moved one level deeper again, to what practitioners now call harness engineering, the design of the whole agent environment, with Martin Fowler’s team, Ethan Mollick, and others writing the early canon.
Three eras in three years: prompt engineering, then context engineering, then harness engineering. Each shift happened because the previous lever stopped paying off. And the tell of where the value sits now is the metric people optimize. In 2026, it is no longer prompt quality. It is the cache-hit rate. Seen against that backdrop, the caveman prompt was the last gasp of prompt engineering, a way to fight a war the serious builders had already left.
More tokens is not just costlier. It is worse.
Here is the part that turns a cost argument into something harder to wave away. Adding tokens does not just raise the bill. It degrades the answer.
The AI lab Chroma published a study in July 2025 testing eighteen frontier models, including the latest from Anthropic, OpenAI, and Google, on how performance changes as input grows. Every one of them got worse as the context lengthened, on simple tasks, well before the window was anywhere near full. The phenomenon has a name, context rot, and three drivers: models attend poorly to the middle of long inputs, costing thirty percent or more in accuracy in Stanford’s earlier work; attention dilutes as the token count climbs; and irrelevant but similar content pulls the model off course. For coding agents, the primary failure mode is no longer raw capability. It is context rot, the noise the agent piles up as it searches and backtracks.
So the tokenmaxxer pays twice. A bigger bill, and a dumber model. The corollary is the most important sentence in this piece for anyone building or buying: curated, minimal, high-yield context is the rare thing that is cheaper and better at once. Efficiency and quality stop being a tradeoff and start being the same project.
What good architecture actually looks like
If yield is an architecture problem, the obvious question is what the architecture is. Jain’s four levers are a useful frame: context quality, model routing, continual learning, and harness design. The reason to trust the levers rather than the vendor who named them is that everyone else arrived at the same four from different directions.
NVIDIA Research argues in its widely read paper that small language models are the future of agentic AI, that a seven-billion-parameter model is ten to thirty times cheaper to run than a frontier model and should handle the bulk of agentic work, with larger models reserved for the hard parts. Gartner says the same in different words: route routine, high-frequency tasks to small or domain-specific models, and gate expensive frontier inference for genuine reasoning. Andreessen Horowitz, in a much-cited May 2026 piece by partner Joe Schmidt, lists the defenses that let an application company survive the labs, and they reduce to the same set, a data flywheel, routing across vendors, cost optimization across model tiers, and governance.
When a vendor, a chipmaker, a research firm, and a venture fund independently describe the same machine, it has stopped being marketing. And the waste is not hypothetical. Jain, whose company sells exactly this, so weigh it accordingly, estimates that roughly ninety-five percent of enterprise AI usage still runs on the most expensive frontier models, even for work a cheaper model could handle. Cognition’s Scott Wu, whose firm builds the coding agent Devin, puts the cost efficiency available on routine work at five to ten times. The default, in other words, is to overpay for almost everything.
And routing buys more than savings. When a government can switch off a single lab’s flagship overnight, as the US did to Anthropic’s two most capable models in June under an export-control order, spreading work across providers stops being only a cost strategy and becomes a resilience one. Concentration is a bill that arrives all at once.

[The four levers of execution efficiency. Context quality, model routing, continual learning, and harness design, shown as the stack that determines token yield, with the converging sources that name each.]
It helps to see the machine assembled, because the contrast with the naive system is the entire argument.
The naive system, the one most enterprises are running right now, points one frontier model at every request, shovels the whole document corpus into context, routes nothing, caches nothing with any discipline, and remembers nothing about what worked last time. High token count, low yield, and thanks to context rot, worse answers. The high-yield system has five working parts:
- A context layer that retrieves the minimum viable context for a query rather than the whole corpus. This is the part that fights context rot directly.
- A router that classifies the task and sends it to the right model tier, gating frontier reasoning instead of defaulting to it.
- A harness that controls reasoning effort, reuses the cache, and evicts dead context from the working set. This is the part the caveman crowd never saw.
- A learning loop in which every run leaves behind evals, labels, and corrections that sharpen retrieval and routing over time.
- A metering layer that attributes token cost down to the workflow, so yield is something you can actually see.
I have been building one of these, a knowledge-graph platform I call Project Nexus, so let me be concrete about the context layer, which is where most of the waste and most of the moat live. The design choices map straight onto the levers.
It is ontology-first, meaning a typed schema constrains what extraction can produce, which is the only thing that gives the resulting graph reliable structure instead of a pile of loosely related text. Retrieval is hybrid: vector similarity for semantic matches, keyword search for exact phrases, and graph traversal for the relationship-shaped questions that vector search cannot answer, with the rankings fused cheaply at the end. That is what lets the system pull the few connected facts a question actually needs rather than the nearest large blob of text.
Every node carries a confidence score and a validity window, and the score decays over time on a curve, climbing back up when a fresh source corroborates it, so stale facts fade out of retrieval on their own without anyone pruning them by hand. That last piece is the continual-learning lever made literal. And every claim in an answer cites the specific source it came from, which is the governance lever, the difference between an answer you can audit and one you have to trust.
The honest version, because a reference architecture sold as a free lunch is just a brochure: I built it to attack the context-quality and learning levers specifically, the system meters the real token cost of every query against what naive retrieval would have spent on the same question, and in my own corpus, that gap is large. The number I care about more is that the gap is visible at all, because you cannot manage a yield you do not measure. The point is not that a knowledge graph is the answer. The point is that the work is in the architecture, and a graph is one way to do it.
It also comes with real tradeoffs, and pretending otherwise is how you get a brochure. Routing adds orchestration overhead. Knowledge graphs are costly to build, add traversal latency, and break in their own ways, the same entity splitting into three, queries pointed at the wrong shape of the problem, because models reason over text rather than graph topology. Even caching has a ceiling, since cached context still occupies the window and still costs attention on every output token. Proper architecture means managing those tradeoffs, not escaping them.
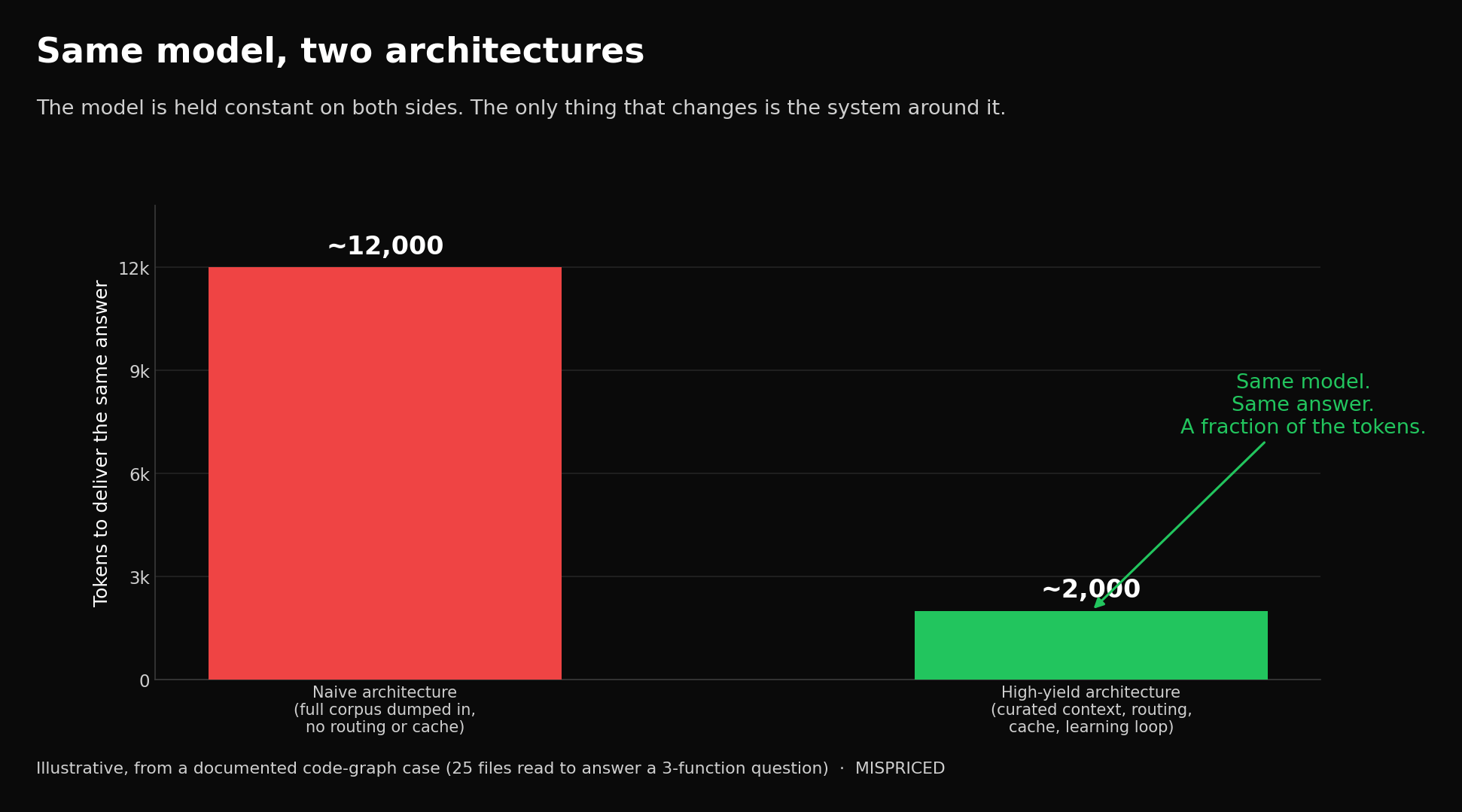
[Anatomy of a high-yield system. The naive architecture (one frontier model, full corpus dumped in, no routing, no caching, no loop) versus the high-yield architecture (curated context layer, router, disciplined harness, learning loop, metering), with the same task producing far more useful work per token on the right.]
For an investor, the architecture is also a lens. Pair it with the three tests Schmidt offers for telling a durable company from a thin wrapper, and you have a diagnostic you can run from the outside. How many steps does the work take, and how complex are the tools required to support it? Is the company a system that the customer runs their work through, or a tool sitting on top of a system they already have? And is its performance judged against benchmark scores or against the customer’s own profit and loss? A company that owns the system of work passes all three. A wrapper on someone else’s model passes none.
Where the value accrues
Which is the investment thesis, finally stated plainly? If execution efficiency is the lever, value accrues to whoever owns the architecture that produces it, and that is a very different map of winners than the one the market is currently pricing.
Schmidt’s framing is the cleanest version. The labs own what a16z calls the Yellow Brick Road, the horizontal, low-step work that improves with raw model capability, code generation, writing, image creation, the things a generic coworker does well. Everything else lives in the rest of Oz, the vertical, multi-step, regulated work where the value comes from the scaffolding around the model and not the model itself. Both can win.
But the application companies that wander onto the road, plugging off-the-shelf connectors into a frontier model and shipping an orchestration layer, are walking into the labs’ own product. The ones that survive own the data capture, the workflow, and the governance for a specific domain, and they compound an advantage with every deployment. The model underneath is fungible. The system of work is not.
Even the labs concede the point: OpenAI and Anthropic have both stood up forward-deployed enterprise units to configure their models for specific industries, which is not what you do if you believe the next model release handles everything.
If that still sounds like a venture pitch, consider who else is now making it. In mid-June, Satya Nadella, whose own company is busy building models to lessen its dependence on OpenAI, told businesses to stop reaching for the most powerful model for work that does not need it, and argued the prize is a frontier ecosystem, not a frontier model.
His framing is almost word-for-word Schmidt’s. Companies should own the learning loop that compounds their institutional knowledge, treat the underlying general-purpose model as something to swap out as the technology turns over, and recognize that the durable intellectual property is the proprietary system built on top, not the model underneath. When the chief executive of the most valuable software company on earth tells you the model is the fungible part, the contrarian read has become the consensus.
The macro floor under all of this comes from IBM’s Arvind Krishna, who did the arithmetic on the buildout. Roughly a hundred gigawatts of committed AI data-center capacity at sixty to eighty billion dollars of silicon per gigawatt implies six to eight trillion dollars of infrastructure, which on a five-to-seven-year payback would require one to two trillion dollars of new annual revenue to justify. “That much incremental revenue I don’t believe is there,” he said, and he expects the frontier models themselves to commoditize, with maybe two or three builders surviving. Stack his view on Schmidt’s, and the picture resolves. The builders of raw capability commoditize toward cost. The owners of the durable layer keep the margin. Execution efficiency is what defines that durable layer.
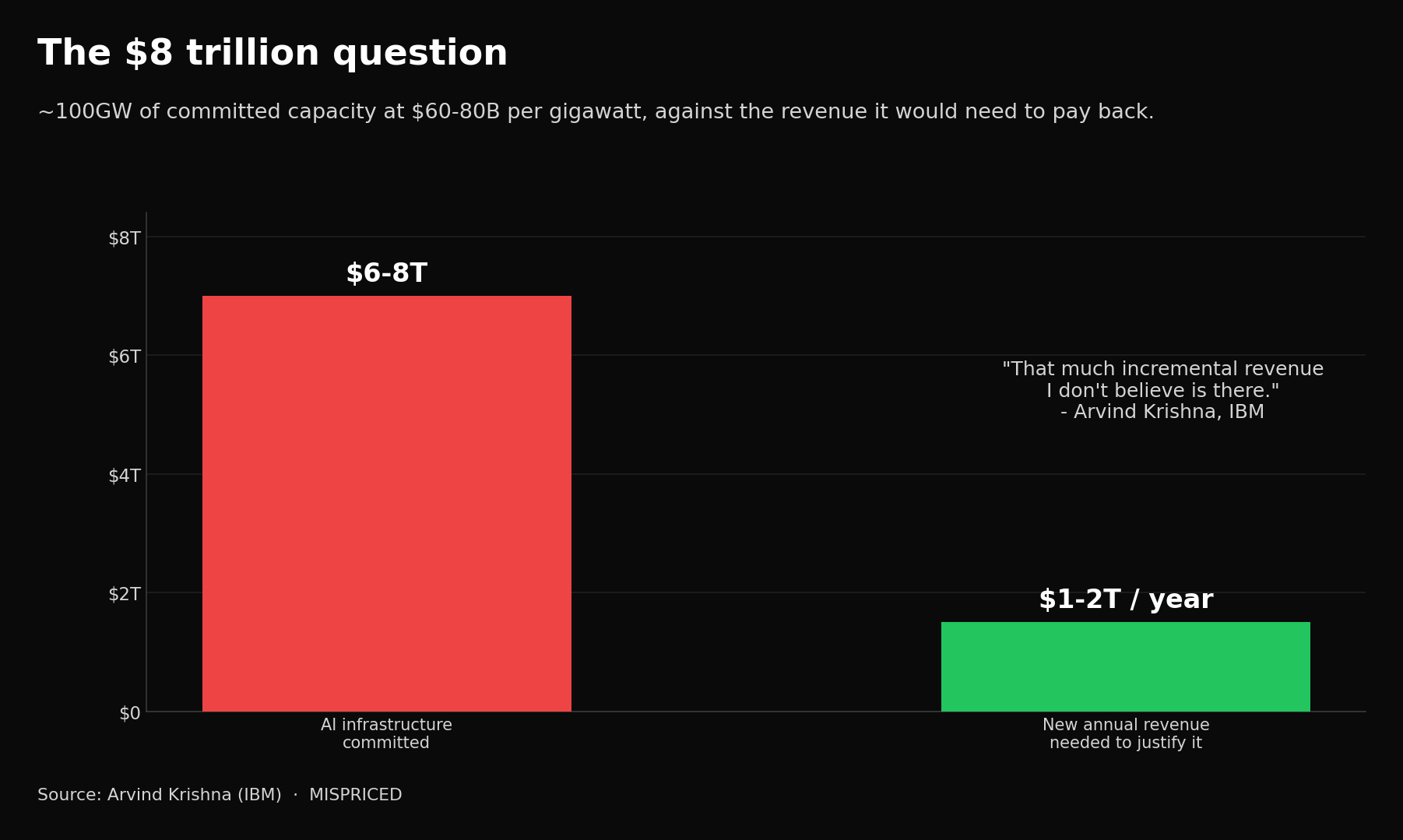
[Krishna’s $8 trillion gap. Committed AI infrastructure spend (~$6-8T) against the $1-2T in new annual revenue it would need to generate to justify the payback.]
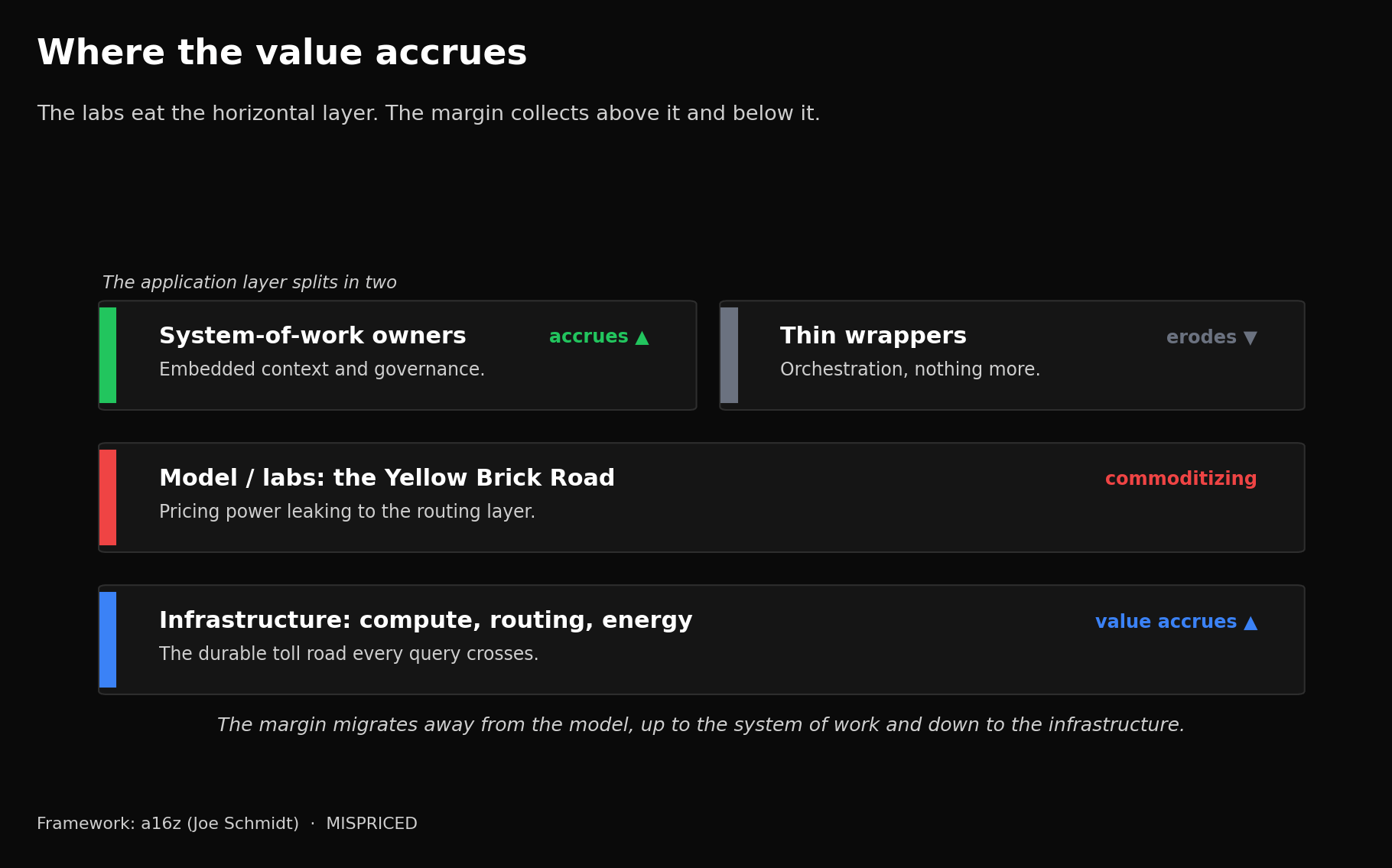
[Where the value accrues. The labs eat the horizontal “Yellow Brick Road” layer; durable value collects in the infrastructure beneath and the vertical, embedded, governance-heavy application layer above.]
And the market is already pricing the shift. In early June, CNBC’s Deirdre Bosa reported that model routing has become a direct problem for OpenAI and Anthropic, both of which built their businesses, and the IPO expectations around them, on the assumption of enormous demand at premium prices. If easy, high-volume work moves to cheaper models, including open-source ones, the labs keep only the hard jobs, and pricing power shifts toward whoever decides which model runs when.
The labs see it coming. Anthropic has moved from flat-rate enterprise pricing toward per-token billing and cut off some heavy third-party token consumers, and both ship tiered model families, which is itself an admission that not every task needs the top of the line. The fair read, and the one SemiAnalysis’s Dylan Patel offers, is that routing does not sink the frontier labs but bends their pricing from charging more toward being used more efficiently. Which is the same conclusion from the other end of the telescope: the model is becoming a commodity input, and the margin migrates to whoever architects around it.
The capital is already moving there. In June, OpenRouter, which routes across more than four hundred models and sells companies a way out of single-vendor lock-in, raised a hundred and thirteen million dollars at a 1.3 billion dollar valuation, led by Alphabet’s growth fund with the venture arms of NVIDIA, Snowflake, and Databricks alongside. Its chief executive reduced the thesis to a sentence: running inference at scale is a multi-model problem, and the era of picking a single model is over. The Linux Foundation, for its part, has launched a Tokenomics Foundation to standardize how all of this gets measured in the first place.
The finance function is wiring the meters to match. The FinOps Foundation reports that ninety-eight percent of practices now manage AI spend, up from sixty-three percent a year earlier, and the question has shifted from how much we spend to cost-per-workflow and return-on-workflow, with model rightsizing now squarely inside the mandate. The market is learning, through its accounting departments, to price yield.
This is also where I should disclose my own position, because it cuts against type. I work as a solution consultant at Adobe, which Morningstar downgraded this spring from a wide to a narrow economic moat, alongside Salesforce, Workday, and a cluster of other application-layer software names, on exactly the thesis that the labs will eat the application layer. I do not think that thesis is wrong so much as incomplete.
Morningstar itself noted it has watched several software-is-dead episodes over twenty-six years and does not believe software moats evaporated overnight. The surviving application-layer moats are the ones built on the system of work, the embedded context, the governance, and the execution efficiency that a horizontal model cannot replicate from the outside. Whether any given incumbent has built that is the question worth asking, and it is the question this framework is for.
The objection that does not survive contact
The strongest case against everything above is that none of it lasts, because models simply get cheap enough that efficiency stops mattering. Tokens have fallen in price before and will again, so why architect around a cost that is trending to zero.
The numbers say the opposite. Gartner projects that by 2030 the cost of running inference on a trillion-parameter model will fall more than ninety percent. In the same breath it warns that agentic workloads consume five to thirty times more tokens per task than a chatbot does, so as consumption outruns price, total inference bills rise rather than fall. Goldman Sachs models a twenty-four-fold increase in token consumption by 2030. And Gartner’s sharpest point is the one that should end the debate: cheap tokens do not fix architectural inefficiency, they hide it, until agentic scale drags it back into the light.
The cheaper a token gets, the more of them a careless system will burn, which makes yield matter more, not less. Falling prices are not a reprieve from this discipline. They are the reason it becomes unavoidable. The labs are behaving as if they know it. OpenAI, under the same routing pressure, is reportedly weighing token price cuts and has built out a full ladder, from a ten-cent nano model to a thirty-dollar flagship, so that customers who are going to route do it inside the OpenAI stack rather than across to open-source rivals. That is not the posture of a company that expects to keep charging a premium for every token.
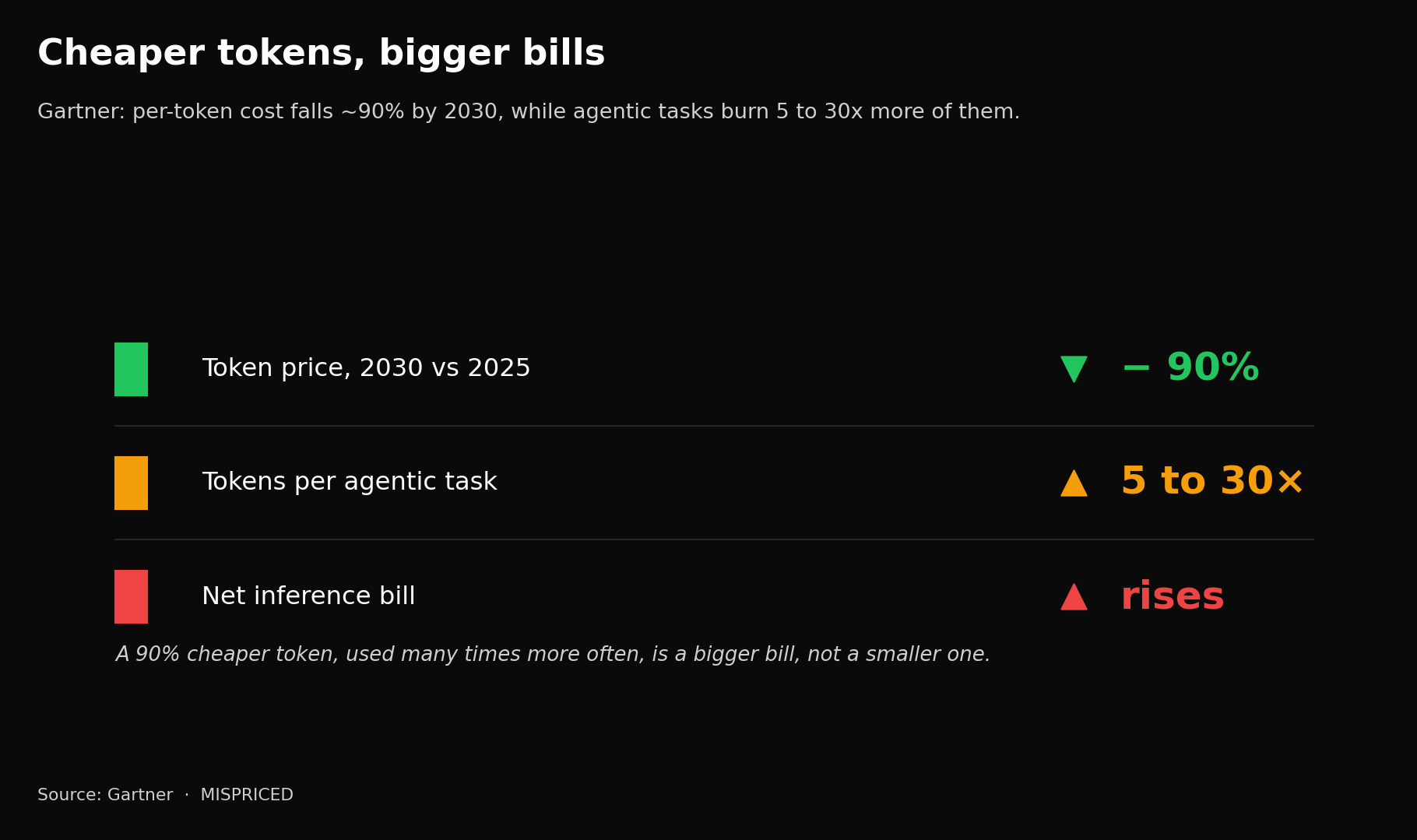
[Cheaper tokens, bigger bills. Gartner’s projected ~90% drop in per-token cost by 2030 against the 5-30x rise in tokens consumed per agentic task, and the net effect on total spend.]
The point the caveman missed
The caveman prompt was not stupid. It was looking in the only place a prompt can look, at the words on the way out, and trying to make them shorter. The whole industry made the same mistake at a larger scale, mistaking a usage number on a leaderboard for a measure of value, and calling the resulting waste a strategy.
The real lever was always one level down, in the system around the model, where the context gets curated before it is sent, the work gets routed to the cheapest model that can do it, the cache gets reused instead of rebuilt, and the system quietly learns what worked the last ten thousand times.
The proof arrived this month, on a schedule no one would have scripted. On a Friday in June, the US government switched off Anthropic’s two most capable models worldwide with an export-control order. By the next day, OpenRouter had shipped Fusion, a tool that fans a question out to a panel of ordinary models, has a judge model weigh the answers, and synthesizes one result. On a hard research benchmark, a panel of three budget models, none of them frontier, landed within a single point of the banned Fable 5 at roughly half the cost.
It is no free lunch. A panel call runs several times the price of a single one, and it is no substitute for a frontier model on the hardest long-horizon work. But the headline is hard to miss. The most capable model on the planet went dark on Friday, and by Saturday a stack of commodity models had matched it, because the answer was assembled in the architecture rather than bought in the model. As one writer put it, that is not magic, it is architecture.
[A cheap panel matched the model that the government banned. OpenRouter’s Fusion on the DRACO benchmark, days after Fable 5 was pulled. Source: OpenRouter.]
Tokenmaxxing measured the wrong thing, and it is dead. Token yield is the thing, and the companies learning to produce more of it per dollar are not running a cost-savings program. They are building the one moat the labs cannot reach across, because the model is fungible, and the system of work is not. The cost panic of 2026 will be remembered as the moment the market finally learned to tell the two apart.
---
Disclosure: The author works as a solution consultant at Adobe, referenced above. This piece concerns the architecture of execution efficiency across the AI application and infrastructure layers and is not investment advice. Project Nexus is a personal project described here to illustrate an architectural argument, not as a commercial offering, and the cost figures cited from it are self-measured. Do your own work before making any decision.